Problem description
https://leetcode-cn.com/problems/regular-expression-matching/
Solution
回溯法
首先判断首字母是否相等为 firstMatch, 遇到.时默认为匹配
如果有*号 ,而模式串 p 只有两个的话,那么*号应该是在 p[1].
对于*号的处理要么是不将前面的包含其中,要么是继续重复匹配。
回溯法思路中,自己犯了一个思维惯性,因为 * 在正则中是贪婪匹配的,所以自己进行 dfs 时,直接按最长的来,导致了超时。在做题中,匹配串长度是固定的,我的目标是尽可能快地确认 模式串的与匹配串匹配。遇到 ‘*’ 时应该先匹配不包含前面元素,再进行包含的遍历。
题解在遍历时是从头至尾进行一一比较进行遍历。遍历过程不断去掉二者已匹配的部分,比较剩余部分直至二者刚好比较结束。则为匹配。我自己在做回溯时,采取的是传统的回溯策略,记录 start 值,通过回溯遍历出 模式串 p 的所有可能字符串与 s 比较,匹配成功则立刻返回。这样的问题是遍历 p 的可能性太耗时,比如遇到.必须遍历 26种可能,这样无疑很耗时。
回溯法时间复杂度很长就对了。。。官方题解的数字也不知道怎么算出来的
动态规划
自己看了官方题解了解到这道题可以使用 dp 缩短时间复杂度为 $O(TP)$( T 和 P 分别表示匹配串和模式串的长度)。
自己看的是自底向上的解法。
这个方法就很骚了,我跟着画了图一步步才弄明白。
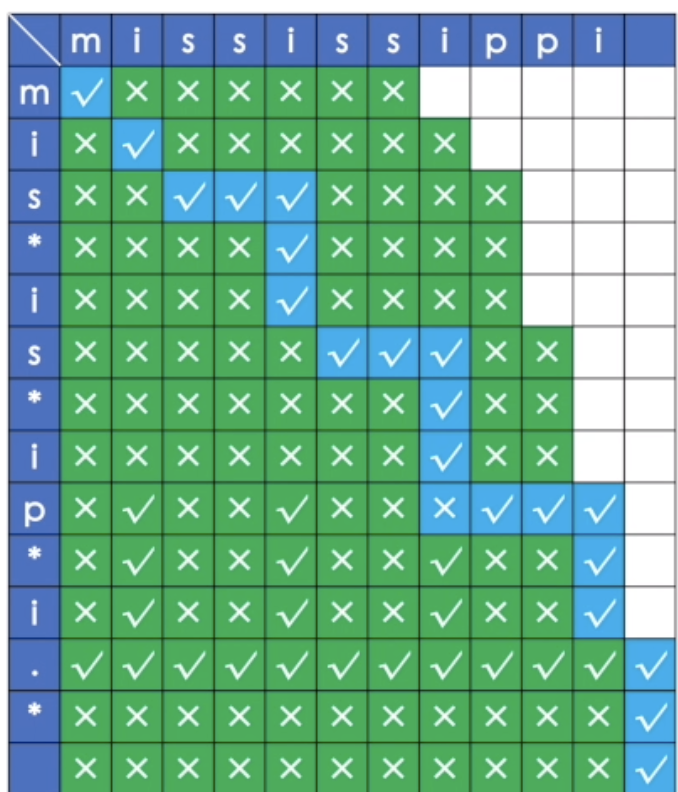
盗张大佬的图分析下。
dp 是一个 (s.length + 1) X (p.length + 1)二维数组,最后会解释这里length为啥要加一。dp[i][j] = true 表示 s[i..s.length]与 p[j..p.length]相匹配。
遇到* 时, dp[i][j] = dp[i][j + 2] || firstMatch && dp[i + 1][j] 前面优先看不包含的情况, || 后面表示 是重复当前字母的情况。 如果首字母相等,再判断 s[i + 1..s.length] == p[ j..p.length],这里尤为烧脑 。这里 或 前后顺序是不能调整的。
不是* 则直接 dp[i][j] = firstMatch && dp[i + 1][j + 1]. (s[i] = p[j] && s[i + 1..s.length] == p[j + 1..p.length])
最后来解释下为啥dp 的 size 中需要 length + 1,最后的一个空行/空列表示 当前匹配串为空串,模式串为空串。所以理所当然 dp[s.length][j.length] = true. 表示空串 = 空串。 同理通配符的 dp[0][0]=true 也是因为这个原因。 考虑匹配串为空串与模式串其余字符的匹配情况呀。
时间复杂度:$O(TP)$ ( T 和 P 分别表示匹配串和模式串的长度)
空间复杂度:$O(TP)$
Code
1 | 回溯 |
1 | dp |