转自piasy兄的拆RxJava
概述
顺着常用的场景/用例出发,理解整个过程、结构、原理,不要沉迷于细节,先对常用的内容有一个全局的概览,每一块的细节再按需深入。入手新项目也是这个思路。
从四个方面分析Rxjava
- 事件流源头(observable)怎么发出数据
- 响应者(subscriber)怎么收到数据
- 怎么对事件流进行操作(operator/transformer)
- 以及整个过程的调度(scheduler)
以及一些新鲜的词语如
demo
1
2
3
4
5
| Observable.just("Hello world")
.subscribe(word -> {
System.out.println("got " + word + " @ "
+ Thread.currentThread().getName());
});
|
订阅过程
just
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
public static <T> Observable<T> just(final T value) {
return ScalarSynchronousObservable.create(value);
}
public static <T> ScalarSynchronousObservable<T> create(T t) {
return new ScalarSynchronousObservable<T>(t);
}
protected ScalarSynchronousObservable(final T t) {
super(RxJavaHooks.onCreate(new JustOnSubscribe<T>(t)));
this.t = t;
}
|
- 我们创建的是
ScalarSynchronousObservable,一个 Observable 的子类。
- 我们先跳过
RxJavaHooks,从名字可以得知它是用来做一些 hook 的工作的,那我们就先认为它什么也不做。所以我们传给父类构造函数的就是 JustOnSubscribe,一个 OnSubscribe 的实现类。
Observable 的构造函数接受一个 OnSubscribe,它是一个回调,会在 Observable#subscribe 中使用,用于通知 observable 自己被订阅, 进入subscribe方法
subscribe
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
| public final Subscription subscribe(final Action1<? super T> onNext) {
Action1<Throwable> onError =
InternalObservableUtils.ERROR_NOT_IMPLEMENTED;
Action0 onCompleted = Actions.empty();
return subscribe(new ActionSubscriber<T>(onNext,
onError, onCompleted));
}
public final Subscription subscribe(Subscriber<? super T> subscriber) {
return Observable.subscribe(subscriber, this);
}
static <T> Subscription subscribe(Subscriber<? super T> subscriber,
Observable<T> observable) {
subscriber.onStart();
if (!(subscriber instanceof SafeSubscriber)) {
subscriber = new SafeSubscriber<T>(subscriber);
}
try {
RxJavaHooks.onObservableStart(observable,
observable.onSubscribe).call(subscriber);
return RxJavaHooks.onObservableReturn(subscriber);
} catch (Throwable e) {
}
}
````
1. 我们首先对传入的 Action 进行包装,包装为 `ActionSubscriber`,一个 `Subscriber` 的实现类。
2. 调用 `subscriber.onStart()` 通知 `subscriber` 它已经和 `observable` 连接起来了。这里我们就知道,`onStart()` 就是在我们调用 `subscribe()` 的线程执行的。
3. 如果传入的 `subscriber` 不是 `SafeSubscriber`,那就把它包装为一个 `SafeSubscriber`。
4. 我们再次跳过` hook`,认为它什么也没做,那这里我们调用的其实就是 `observable.onSubscribe.call(subscriber)`。这里我们就看到了前面提到的 `onSubscribe` 的使用代码,在我们调用 `subscribe()` 的线程执行这个回调。
5. 跳过 `hook`,那么这里就是直接返回了 `subscriber`。`Subscriber` 继承了 `Subscription`,用于取消订阅。
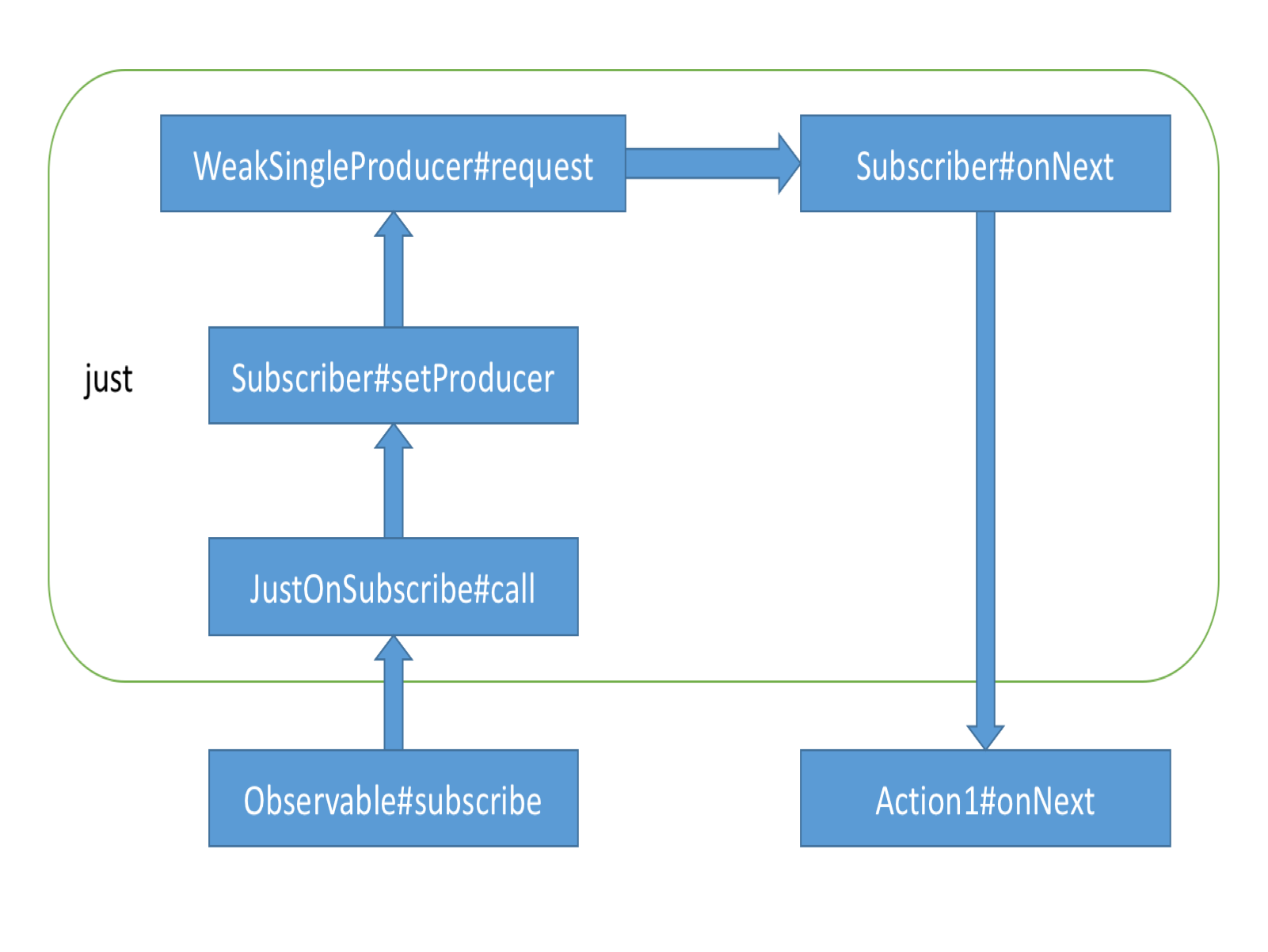
但是 Hello world 是怎么被传递到打印的代码里的呢?就在 observable.onSubscribe.call(subscriber) 中。
### OnSubscribe
在just() 的实现中,我们创建了一个 `JustOnSubscribe` 吗?这里我们执行的就是它实现的 `call()` 函数:
``` java
static final class JustOnSubscribe<T> implements OnSubscribe<T> {
@Override
public void call(Subscriber<? super T> s) {
s.setProducer(createProducer(s, value));
}
}
static <T> Producer createProducer(Subscriber<? super T> s, T v) {
return new WeakSingleProducer<T>(s, v);
}
|
为 subscriber 设置了一个 WeakSingleProducer。
在 RxJava 1.x 中,数据都是从 observable push 到 subscriber 的,但要是 observable 发得太快,subscriber 处理不过来,该怎么办?一种办法是,把数据保存起来,但这显然可能导致内存耗尽;另一种办法是,多余的数据来了之后就丢掉,至于丢掉和保留的策略可以按需制定;还有一种办法就是让 subscriber 向 observable 主动请求数据,subscriber 不请求,observable 就不发出数据。它俩相互协调,避免出现过多的数据,而协调的桥梁,就是 producer。producer 的内容这里不展开。
request
进入 WeakSingleProducer#request() 的实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
static final class WeakSingleProducer<T> implements Producer {
@Override
public void request(long n) {
Subscriber<? super T> a = actual;
if (a.isUnsubscribed()) {
return;
}
T v = value;
try {
a.onNext(v);
} catch (Throwable e) {
Exceptions.throwOrReport(e, a, v);
return;
}
if (a.isUnsubscribed()) {
return;
}
a.onCompleted();
}
}
|
在 request() 中,终于调用了 subscriber 的 onNext() 和 onCompleted(),那么,Hello world 就传递到了我们的 Action 中,并被打印出来了。
完整过程
操作符
以map为例
1
2
3
4
5
6
| Observable.just("Hello world")
.map(String::length)
.subscribe(word -> {
System.out.println("got " + word + " @ "
+ Thread.currentThread().getName());
});
|
进入map方法
map
1
2
3
4
5
6
7
8
|
public final <R> Observable<R> map(Func1<? super T, ? extends R> func) {
return create(new OnSubscribeMap<T, R>(this, func));
}
public static <T> Observable<T> create(OnSubscribe<T> f) {
return new Observable<T>(RxJavaHooks.onCreate(f));
}
|
map 的实现采用了 create + OnSubscribe(RxJava #4097);
这里实际上是 OnSubscribeMap 干活了。
OnSubscribeMap
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| public final class OnSubscribeMap<T, R> implements OnSubscribe<R> {
final Observable<T> source;
final Func1<? super T, ? extends R> transformer;
public OnSubscribeMap(Observable<T> source,
Func1<? super T, ? extends R> transformer) {
this.source = source;
this.transformer = transformer;
}
@Override
public void call(final Subscriber<? super R> o) {
MapSubscriber<T, R> parent =
new MapSubscriber<T, R>(o, transformer);
o.add(parent);
source.unsafeSubscribe(parent);
}
}
|
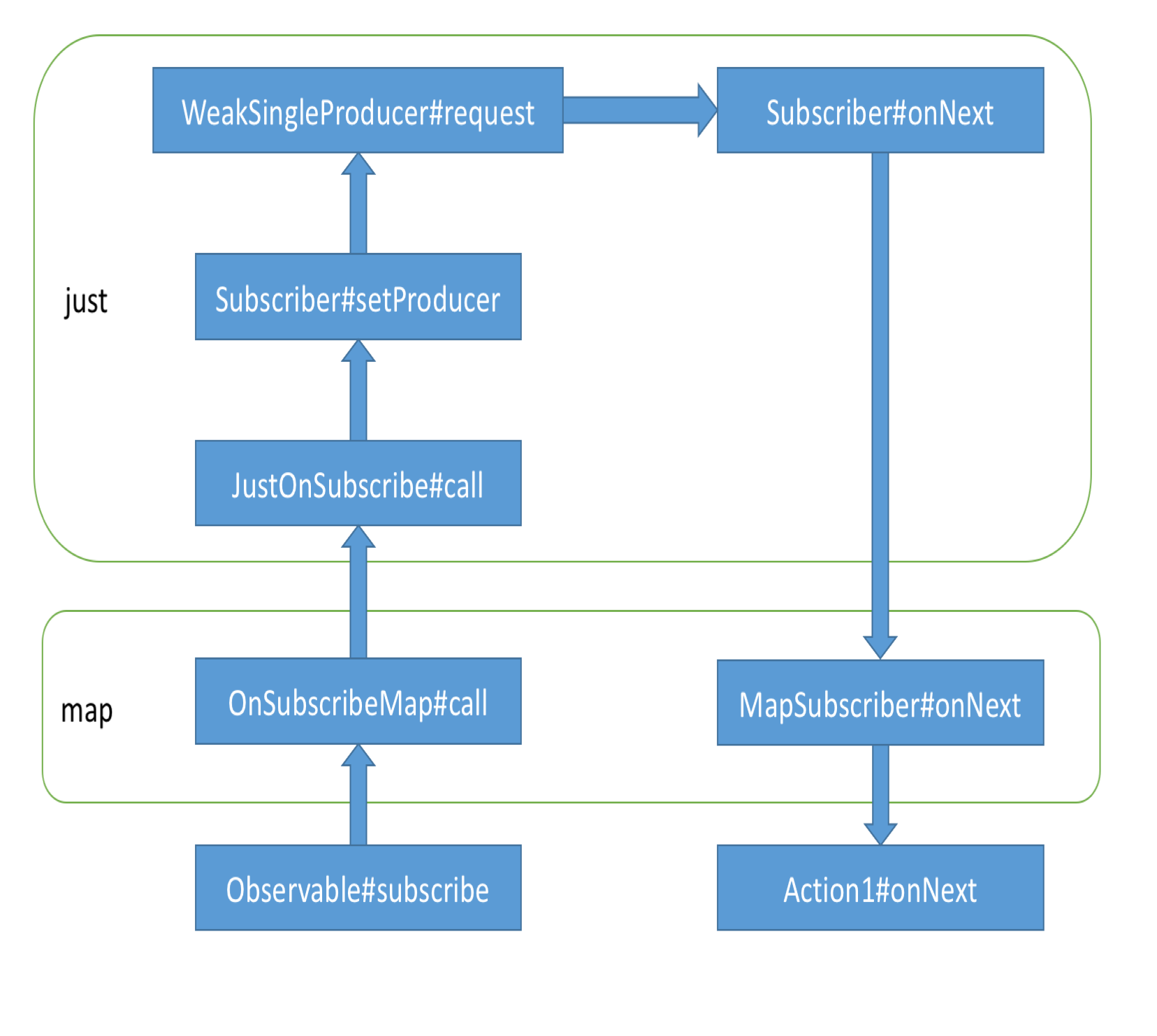
- 利用传入的 subscriber 以及我们进行转换的 Func1 构造一个 MapSubscriber。
- 把一个 subscriber 加入到另一个 subscriber 中,是为了让它们可以一起取消订阅。
- unsafeSubscribe 相较于前面的 subscribe,可想而知就是少了一层 SafeSubscriber 的包装。为什么不要包装?因为我们会在最后调用 Observable#subscribe 时进行包装,只需要包装一次即可。
转换的代码依然没有出现,它在 MapSubscriber 中。
MapSubscriber
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| static final class MapSubscriber<T, R> extends Subscriber<T> {
final Subscriber<? super R> actual;
final Func1<? super T, ? extends R> mapper;
boolean done;
public MapSubscriber(Subscriber<? super R> actual,
Func1<? super T, ? extends R> mapper) {
this.actual = actual;
this.mapper = mapper;
}
@Override
public void onNext(T t) {
R result;
try {
result = mapper.call(t);
} catch (Throwable ex) {
Exceptions.throwIfFatal(ex);
unsubscribe();
onError(OnErrorThrowable.addValueAsLastCause(ex, t));
return;
}
actual.onNext(result);
}
}
|
MapSubscriber 依然很直观:
- 上游每新来一个数据,就用我们给的
mapper 进行数据转换。
- 再把转换之后的数据发送给下游。
这里要解释一下“上游”和“下游”的概念:按照我们写的代码顺序,just 在 map 的上面,Action1 在 map 的下面,数据从 just 传递到 map 再传递到 Action1,所以对于 map 来说,just 就是上游,Action1 就是下游。数据是从上游(Observable)一路传递到下游(Subscriber)的,请求则相反,从下游传递到上游。
完整过程
线程调度
我们所有的过程都是通过函数调用完成的,都在 subscribe 所在的线程执行。RxJava 进行异步非常简单,只需要使用 subscribeOn 和 observeOn 这两个操作符即可。既然它俩都是操作符,那流程上就是和 map 差不多的,这里我们主要关注线程调度的实现原理。
demo:
1
2
3
4
5
6
7
8
| Observable.just("Hello world")
.map(String::length)
.subscribeOn(Schedulers.computation())
.observeOn(AndroidSchedulers.mainThread())
.subscribe(len -> {
System.out.println("got " + len + " @ "
+ Thread.currentThread().getName());
});
|
subscribeOn
1
2
3
4
5
6
7
| public final Observable<T> subscribeOn(Scheduler scheduler) {
if (this instanceof ScalarSynchronousObservable) {
return ((ScalarSynchronousObservable<T>)this)
.scalarScheduleOn(scheduler);
}
return create(new OperatorSubscribeOn<T>(this, scheduler));
}
|
还记得上面的 just 吗?它创建的就是 ScalarSynchronousObservable,但是这个特殊情况我们先跳过,我们看普通的情况:通过 create + OperatorSubscribeOn 实现。
OperatorSubscribeOn
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
| public final class OperatorSubscribeOn<T> implements OnSubscribe<T> {
final Scheduler scheduler;
final Observable<T> source;
public OperatorSubscribeOn(Observable<T> source, Scheduler scheduler) {
this.scheduler = scheduler;
this.source = source;
}
@Override
public void call(final Subscriber<? super T> subscriber) {
final Worker inner = scheduler.createWorker();
subscriber.add(inner);
inner.schedule(new Action0() {
@Override
public void call() {
final Thread t = Thread.currentThread();
Subscriber<T> s = new Subscriber<T>(subscriber) {
@Override
public void onNext(T t) {
subscriber.onNext(t);
}
@Override
public void onError(Throwable e) {
try {
subscriber.onError(e);
} finally {
inner.unsubscribe();
}
}
@Override
public void onCompleted() {
try {
subscriber.onCompleted();
} finally {
inner.unsubscribe();
}
}
@Override
public void setProducer(final Producer p) {
subscriber.setProducer(new Producer() {
@Override
public void request(final long n) {
if (t == Thread.currentThread()) {
p.request(n);
} else {
inner.schedule(new Action0() {
@Override
public void call() {
p.request(n);
}
});
}
}
});
}
};
source.unsafeSubscribe(s);
}
});
}
}
|
Worker 也实现了 Subscription,所以可以加入到 Subscriber 中,用于集体取消订阅。- 在匿名
Subscriber 中,收到上游的数据后,转发给下游。
Producer#request 被调用时,如果调用线程就是 worker 的线程(t),就直接把请求转发给上游。- 否则还需要进行一次调度,确保调用上游的
request 一定是在 worker 的线程。
- 在
worker 线程中,把自己(匿名 Subscriber)和上游连接起来。
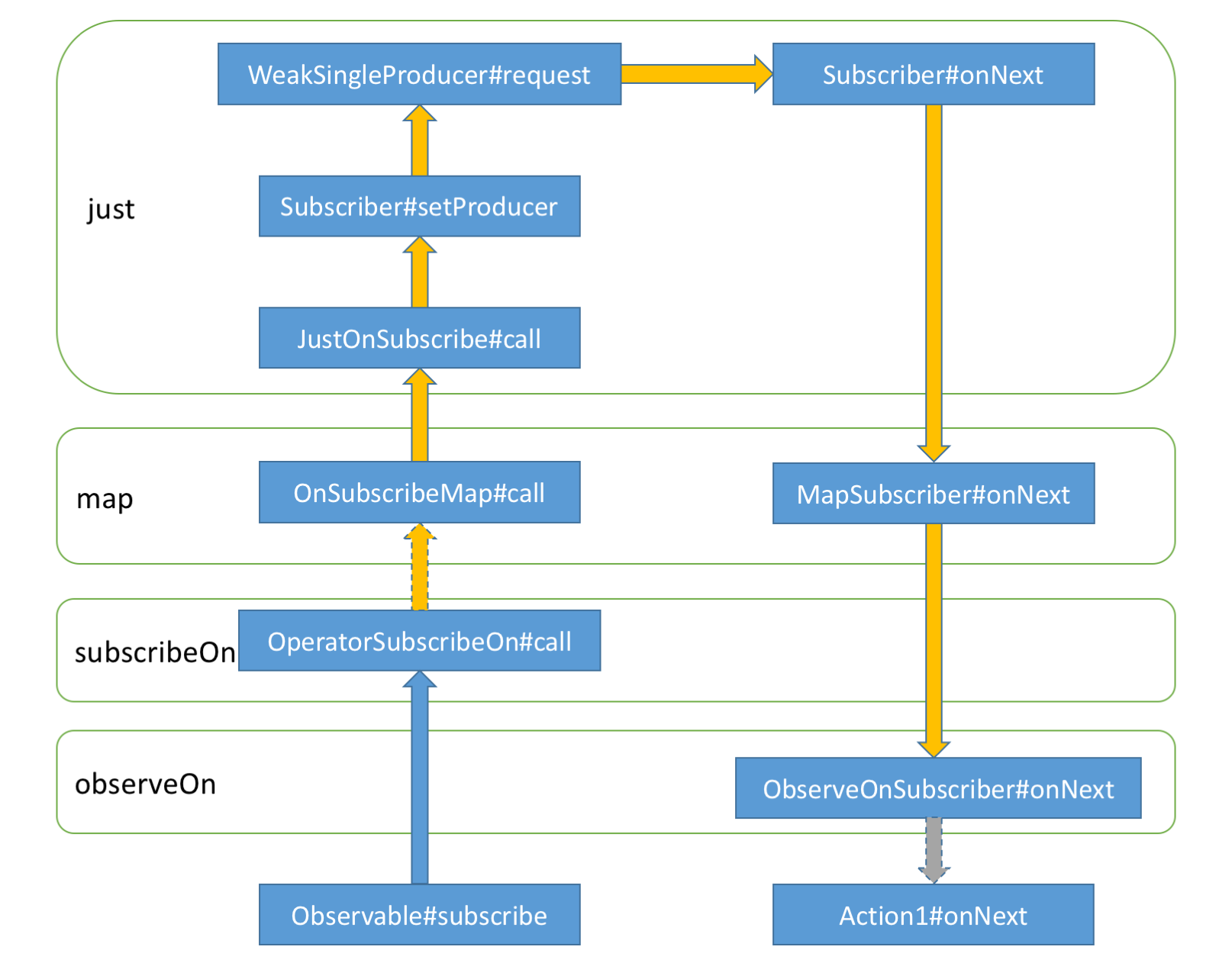
连接上游(可能会触发请求)、向上游发请求,都是在 worker 的线程上执行的,所以如果上游处理请求的代码没有进行异步操作,那上游的代码就是在 subscribeOn 指定的线程上执行的。这就解释了网上随处可见的一个结论:
subscribeOn 影响它上面的调用执行时所在的线程。
但如果仅仅是记住这么一句话,情况稍微一复杂,就必然蒙圈,所以一定要理解它的工作原理。
另外关于使用多次调用 subscribeOn 的效果,我们这里也就很清楚了,后面的 subscribeOn 只会改变前面的 subscribeOn 调度操作所在的线程,并不能改变最终被调度的代码执行的线程,但对于中途的代码执行的线程,还是会影响到的。
在上面的代码中,收到上游发来的数据之后,我们直接发给了下游,并没有进行线程切换,所以 subscribeOn 并不会改变数据向下游传递时的线程,这一工作由它的搭档 observeOn 完成。
observeOn
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| public final Observable<T> observeOn(Scheduler scheduler) {
return observeOn(scheduler, RxRingBuffer.SIZE);
}
public final Observable<T> observeOn(Scheduler scheduler,
int bufferSize) {
return observeOn(scheduler, false, bufferSize);
}
public final Observable<T> observeOn(Scheduler scheduler,
boolean delayError, int bufferSize) {
if (this instanceof ScalarSynchronousObservable) {
return ((ScalarSynchronousObservable<T>)this)
.scalarScheduleOn(scheduler);
}
return lift(new OperatorObserveOn<T>(scheduler,
delayError, bufferSize));
}
public final <R> Observable<R> lift(
final Operator<? extends R, ? super T> operator) {
return create(new OnSubscribeLift<T, R>(onSubscribe,
operator));
}
|
关注 lift + operator 实现的情况。进入onSubscribeLift
OnSubscribeLift
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| public final class OnSubscribeLift<T, R>
implements OnSubscribe<R> {
final OnSubscribe<T> parent;
final Operator<? extends R, ? super T> operator;
public OnSubscribeLift(OnSubscribe<T> parent,
Operator<? extends R, ? super T> operator) {
this.parent = parent;
this.operator = operator;
}
@Override
public void call(Subscriber<? super R> o) {
Subscriber<? super T> st = RxJavaHooks
.onObservableLift(operator).call(o);
st.onStart();
parent.call(st);
}
}
|
先对下游 subscriber 用操作符进行处理(跳过 hook),然后通知处理后的 subscriber,它将要和 observable 连接起来了,最后把它和上游连接起来。
这里并没有线程调度的逻辑,所以我们看 OperatorObserveOn。
OperatorObserveOn
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| public final class OperatorObserveOn<T> implements Operator<T, T> {
@Override
public Subscriber<? super T> call(Subscriber<? super T> child) {
if (scheduler instanceof ImmediateScheduler) {
return child;
} else if (scheduler instanceof TrampolineScheduler) {
return child;
} else {
ObserveOnSubscriber<T> parent = new ObserveOnSubscriber<T>(
scheduler, child, delayError, bufferSize);
parent.init();
return parent;
}
}
}
|
如果 scheduler 是 ImmediateScheduler/TrampolineScheduler,就什么也不做,否则就把 subscriber 包装为 ObserveOnSubscriber,看来脏活累活都是 ObserveOnSubscriber 干的了。
ObserveOnSubscriber
ObserveOnSubscriber 除了负责把向下游发送数据的操作调度到指定的线程,还负责 backpressure 支持,这导致它的实现比较复杂,所以这里只展示和分析最简单的调度功能。完整代码的分析大家可以自行阅读源码,其中还会涉及到串行访问相关的内容
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| Observable.create(subscriber -> {
Worker worker = scheduler.createWorker();
subscriber.add(worker);
source.unsafeSubscribe(new Subscriber<T>(subscriber) {
@Override
public void onNext(T t) {
worker.schedule(() -> subscriber.onNext(t));
}
@Override
public void onError(Throwable e) {
worker.schedule(() -> subscriber.onError(e));
}
@Override
public void onCompleted() {
worker.schedule(() -> subscriber.onCompleted());
}
});
});
|
observeOn 调度了每个单独的 subscriber.onXXX() 调用,使得数据向下游传递的时候可以切换到指定的线程。这也同样解释了网上随处可见的另一个结论
observeOn 影响它下面的调用执行时所在的线程。
完整过程
backpressure
在前面我们讲 just 时,就已经讲过了 backpressure:
在 RxJava 1.x 中,数据都是从 observable push 到 subscriber 的,但要是 observable 发得太快,subscriber 处理不过来,该怎么办?一种办法是,把数据保存起来,但这显然可能导致内存耗尽;另一种办法是,多余的数据来了之后就丢掉,至于丢掉和保留的策略可以按需制定;还有一种办法就是让 subscriber 向 observable 主动请求数据,subscriber 不请求,observable 就不发出数据。它俩相互协调,避免出现过多的数据,而协调的桥梁,就是 producer。
rxjava2.x的Observable是不存在背压的概念的,背压是下游控制上游流速的一种手段。在rxjava1.x的时代,上游会给下游set一个producer,下游通过producer向上游请求n个数据,这样上游就有记录下游请求了多少个数据,然后下游请求多少个上游就给多少个,这个就是背压。一般来讲,每个节点都有缓存,比如说缓存的大小是64,这个时候下游可以一次性向上游request 64个数据。rxjava1.x的有些操作符不支持背压,也就是说这些操作符不会给下游set一个producer,也就是上游根本不理会下游的请求,一直向下游丢数据,如果下游的缓存爆了,那么下游就会抛出MissingBackpressureException,也就是背压失效了。
在rxjava2.x时代,上述的背压逻辑全部挪到Flowable里了,所以说Flowable支持背压。而2.x时代的Observable是没有背压的概念的,Observable如果来不及消费会死命的缓存直到OOM,所以rxjava2.x的官方文档里面有讲,大数据流用Flowable,小数据流用Observable。
Hook
我们多次遇见了 hook,为了简化逻辑,也多次跳过了 hook,这里我们就看看 hook 有什么用,工作原理是什么。
利用 hook 我们可以站在“上帝视角”,多种重要的节点上,都有 hook。例如创建 Observable(create)时,有 onCreate,我们可以进行任意想要的操作,记录、修饰、甚至抛出异常;以及和 scheduler 相关的内容,获取 scheduler 时,我们都可以进行想要的操作,例如让 Scheduler.io() 返回立即执行的 scheduler。
这些内容让我们可以执行高度自定义的操作,其中就包括便于测试。
其实 hook 的原理并不复杂,在关心的节点(hook point)插桩,让我们可以操控(manipulate)程序在这些节点的行为,至于操控的策略,有一系列函数进行设置、以及清理。
目前和 hook 相关的内容主要在 RxJavaPlugins 和 RxJavaHooks 这两个类中,后者在 v1.1.7 引入,功能更加强大,使用更加方便。