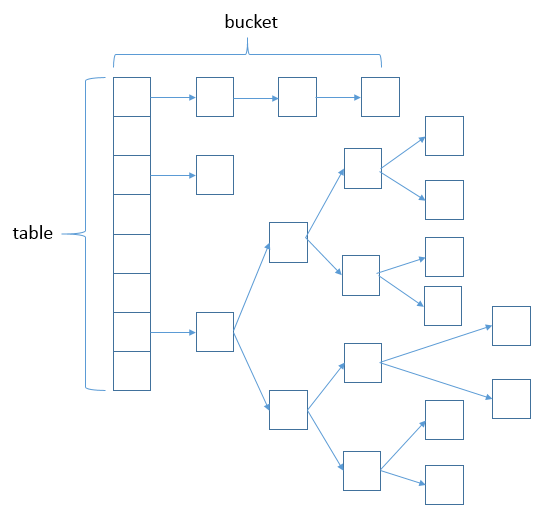
数据结构 位桶 + 链表 + 红黑树 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 static class Node <k,v> implements Map .Entry<k,v> { final int hash; final K key; V value; Node<k,v> next; Node(int hash, K key, V value, Node<k,v> next) { this .hash = hash; this .key = key; this .value = value; this .next = next; } public final K getKey () { return key; } public final V getValue () { return value; } public final String toString () { return key + = + value; } public final int hashCode () { return Objects.hashCode(key) ^ Objects.hashCode(value); } public final V setValue (V newValue) { V oldValue = value; value = newValue; return oldValue; } public final boolean equals (Object o) { if (o == this ) return true ; if (o instanceof Map.Entry) { Map.Entry<!--?,?--> e = (Map.Entry<!--?,?-->)o; if (Objects.equals(key, e.getKey()) && Objects.equals(value, e.getValue())) return true ; } return false ; } }
1 transient Node<k,v>[] table;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 static final class TreeNode <k,v> extends LinkedHashMap .LinkedHashMapEntry<K,V> { TreeNode<k,v> parent; TreeNode<k,v> left; TreeNode<k,v> right; TreeNode<k,v> prev; boolean red; TreeNode(int hash, K key, V val, Node<k,v> next) { super (hash, key, val, next); } final TreeNode<k,v> root () { for (TreeNode<k,v> r = this , p;;) { if ((p = r.parent) == null ) return r; r = p; } }
工作机制
成员变量 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 public class HashMap <K,V> extends AbstractMap <K,V> implements Map <K,V>, Cloneable, Serializable { static final int DEFAULT_INITIAL_CAPACITY = 1 << 4 ; static final int MAXIMUM_CAPACITY = 1 << 30 ; static final float DEFAULT_LOAD_FACTOR = 0.75f ; static final int TREEIFY_THRESHOLD = 8 ; static final int UNTREEIFY_THRESHOLD = 6 ; static final int MIN_TREEIFY_CAPACITY = 64 ; transient Node<k,v>[] table; transient Set<map.entry<k,v>> entrySet; transient int size; transient int modCount; int threshold; final float loadFactor; }
构造函数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 public HashMap (int initialCapacity, float loadFactor) { if (initialCapacity < 0 ) throw new IllegalArgumentException ("Illegal initial capacity: " + initialCapacity); if (initialCapacity > MAXIMUM_CAPACITY) initialCapacity = MAXIMUM_CAPACITY; if (loadFactor <= 0 || Float.isNaN(loadFactor)) throw new IllegalArgumentException ("Illegal load factor: " + loadFactor); this .loadFactor = loadFactor; this .threshold = tableSizeFor(initialCapacity); } public HashMap (int initialCapacity) { this (initialCapacity, DEFAULT_LOAD_FACTOR); } public HashMap () { this .loadFactor = DEFAULT_LOAD_FACTOR; } public HashMap (Map<!--? extends K, ? extends V--> m) { this .loadFactor = DEFAULT_LOAD_FACTOR; putMapEntries(m, false ); }
tableSizeFor(initialCapacity)返回大于等于initialCapacity的最小的二次幂数值。如capacity为9.返回16.
1 2 3 4 5 6 7 8 9 static final int tableSizeFor (int cap) { int n = cap - 1 ; n |= n >>> 1 ; n |= n >>> 2 ; n |= n >>> 4 ; n |= n >>> 8 ; n |= n >>> 16 ; return (n < 0 ) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1 ; }
重要成员函数 1 2 3 4 5 6 static final int hash (Object key) { int h; return (key == null ) ? 0 : (h = key.hashCode()) ^ (h >>> 16 ); } i = (n - 1 ) & hash(key)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 public V get (Object key) { Node<k,v> e; return (e = getNode(hash(key), key)) == null ? null : e.value; } final Node<k,v> getNode (int hash, Object key) { Node<k,v>[] tab; Node<k,v> first, e; int n; K k; if ((tab = table) != null && (n = tab.length) > 0 && (first = tab[(n - 1 ) & hash]) != null ) { if (first.hash == hash && ((k = first.key) == key || (key != null && key.equals(k)))) return first; if ((e = first.next) != null ) { if (first instanceof TreeNode) return ((TreeNode<k,v>)first).getTreeNode(hash, key); do { if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) return e; } while ((e = e.next) != null ); } } return null ; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 public V put (K key, V value) { return putVal(hash(key), key, value, false , true ); } final V putVal (int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node<k,v>[] tab; Node<k,v> p; int n, i; if ((tab = table) == null || (n = tab.length) == 0 ) n = (tab = resize()).length; if ((p = tab[i = (n - 1 ) & hash]) == null ) tab[i] = newNode(hash, key, value, null ); else { Node<k,v> e; K k; if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k)))) e = p; else if (p instanceof TreeNode) e = ((TreeNode<k,v>)p).putTreeVal(this , tab, hash, key, value); else { for (int binCount = 0 ; ; ++binCount) { if ((e = p.next) == null ) { p.next = newNode(hash, key, value, null ); if (binCount >= TREEIFY_THRESHOLD - 1 ) treeifyBin(tab, hash); break ; } if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k)))) break ; p = e; } } if (e != null ) { V oldValue = e.value; if (!onlyIfAbsent || oldValue == null ) e.value = value; afterNodeAccess(e); return oldValue; } } ++modCount; if (++size > threshold) resize(); afterNodeInsertion(evict); return null ; }
resize分为两步:(oldCap:原数组长度, newCap:新数组长度)
将newTable扩充为两倍的table
重新计算index,把节点再放到新的bucket中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 final Node<K,V>[] resize() { Node<K,V>[] oldTab = table; int oldCap = (oldTab == null ) ? 0 : oldTab.length; int oldThr = threshold; int newCap, newThr = 0 ; if (oldCap > 0 ) { if (oldCap >= MAXIMUM_CAPACITY) { threshold = Integer.MAX_VALUE; return oldTab; } else if ((newCap = oldCap << 1 ) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY) newThr = oldThr << 1 ; } else if (oldThr > 0 ) newCap = oldThr; else { newCap = DEFAULT_INITIAL_CAPACITY; newThr = (int )(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY); } if (newThr == 0 ) { float ft = (float )newCap * loadFactor; newThr = (newCap < MAXIMUM_CAPACITY && ft < (float )MAXIMUM_CAPACITY ? (int )ft : Integer.MAX_VALUE); } threshold = newThr; @SuppressWarnings({"rawtypes","unchecked"}) Node<K,V>[] newTab = (Node<K,V>[])new Node [newCap]; table = newTab; if (oldTab != null ) { for (int j = 0 ; j < oldCap; ++j) { Node<K,V> e; if ((e = oldTab[j]) != null ) { oldTab[j] = null ; if (e.next == null ) newTab[e.hash & (newCap - 1 )] = e; else if (e instanceof TreeNode) ((TreeNode<K,V>)e).split(this , newTab, j, oldCap); else { Node<K,V> loHead = null , loTail = null ; Node<K,V> hiHead = null , hiTail = null ; Node<K,V> next; do { next = e.next; if ((e.hash & oldCap) == 0 ) { if (loTail == null ) loHead = e; else loTail.next = e; loTail = e; } else { if (hiTail == null ) hiHead = e; else hiTail.next = e; hiTail = e; } } while ((e = next) != null ); if (loTail != null ) { loTail.next = null ; newTab[j] = loHead; } if (hiTail != null ) { hiTail.next = null ; newTab[j + oldCap] = hiHead; } } } } } return newTab; }